Hi there! I'm Marco Antonio Parra.

Msc. Engineer & Full-Stack Web Developer
Currently, I'm working on freelance projects involving data engineering and web development, bringing my Python, Django, Ruby on Rails, and React expertise to create innovative solutions. I hold a Master's degree in industrial engineering from the University del Bío-Bío, specializing in operations research and optimization models. I'm driven by a passion for web development and data analysis, constantly striving to grow and learn in the ever-evolving field of information technology. I'm committed to contributing to open-source projects and sharing my knowledge with the developer community. Let's connect and collaborate on exciting projects together! Feel free to explore my portfolio at portfolio-mparraf.herokuapp.com and connect on LinkedIn: maaferna. Looking forward to making a positive impact through technology!


MY SKILLS
FRONT END
HTML | CSS | JavaScript | Jquery | React




BACK END
Python | Ruby | SQL (SQLite, MySQL, Postgres) | Node.js




FRAMEWORK
Django | Ruby On Rails | Bootstrap



COMPUTER SCIENCE
Web Development | Algorithms | Metaheuristics | Data Structures | Optimization Model | Web Development | Graphs

TOOLS & DEPLOYMENT
Git | Github | Heroku | Linux



LANGUAGE
Español nativo / Native Spanish
WORK EXPERIENCE
EDUCATION
CERTIFICATIONS & BADGES















PROJECTS
Projects
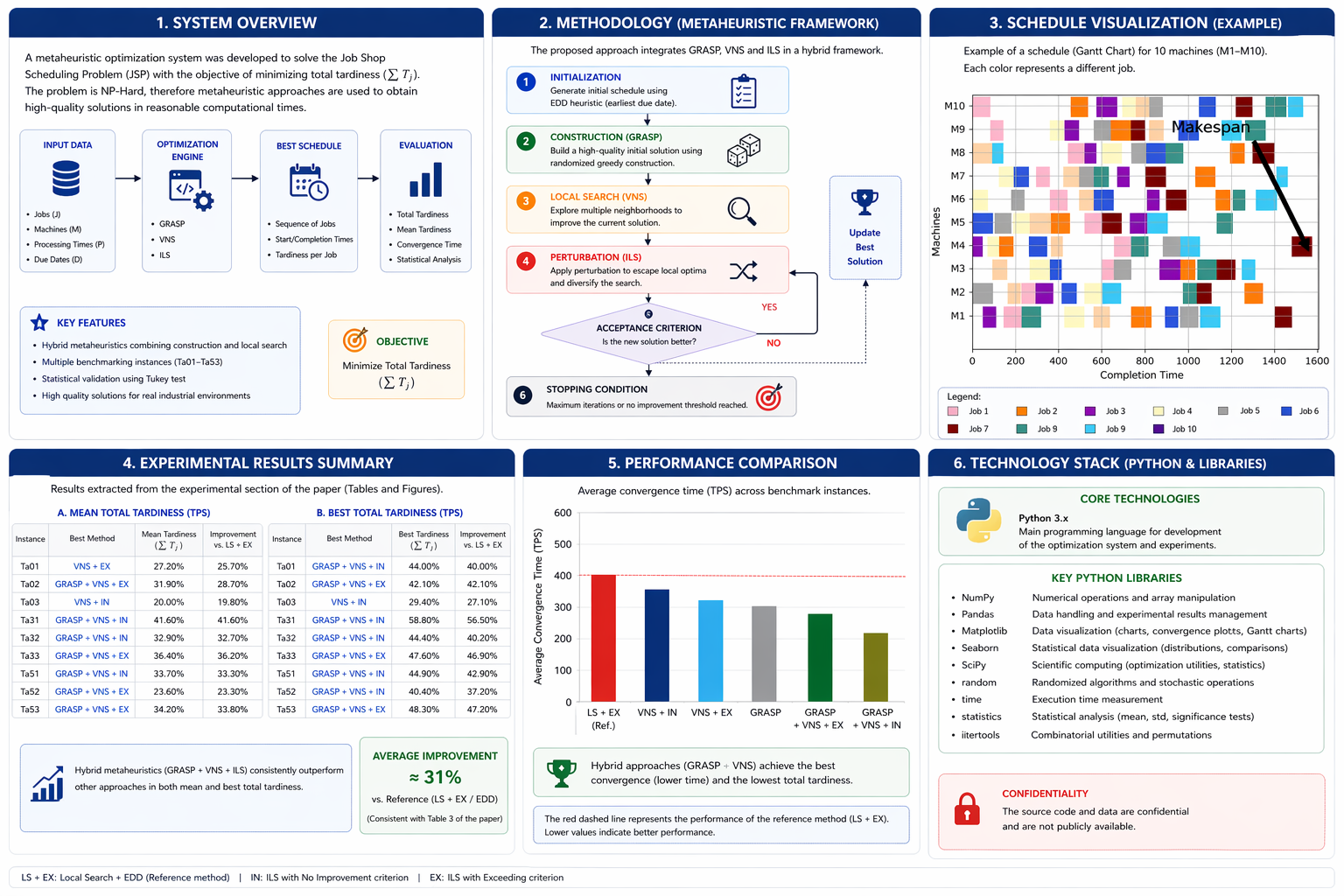
Metaheuristic Optimization for Job Shop Scheduling (NP-hard)
- Metaheuristic Optimization for Job Shop Scheduling (NP-hard)
This project focuses on solving a complex production scheduling problem in a metal-mechanical manufacturing environment, where multiple jobs must be processed across different machines under strict delivery deadlines.
The objective of the system was to minimize total tardiness in a Job Shop Scheduling Problem (JSP), a combinatorial optimization problem classified as strongly NP-hard. Due to the computational complexity of the problem, traditional exact optimization methods become impractical for real-world scenarios, making heuristic and metaheuristic approaches necessary.
The solution was developed as part of an academic research collaboration and implemented as a computational optimization engine capable of generating efficient production schedules within reasonable computational times.
The proposed methodology integrates several metaheuristic strategies, including:
- GRASP (Greedy Randomized Adaptive Search Procedure)
- Variable Neighborhood Search (VNS)
- Iterated Local Search (ILS)
- Hybrid metaheuristic models combining construction and local search phases
The system evaluates candidate schedules using performance metrics such as:
- Total tardiness reduction
- Convergence time
- Exploration capacity
- Statistical significance of results
A statistical validation framework was implemented using the Tukey test to determine whether differences between metaheuristic approaches were statistically significant, ensuring methodological rigor in the evaluation process.
Experimental results demonstrated that hybrid metaheuristic approaches combining GRASP and VNS consistently achieved superior performance compared to standalone methods, particularly for larger problem instances.
The system was implemented using Python and executed in a controlled computational environment to ensure reproducibility and performance evaluation.
This project represents an applied optimization and algorithm design effort that integrates operations research, algorithm engineering, and industrial decision-support systems.
Programming Language
Python 3.x
Main programming language used for implementing metaheuristic optimization algorithms and experimental simulations in Job Shop Scheduling environments.
Core Python Libraries
pandas
Used for:
Data manipulation | Experimental result storage | Scheduling representation | CSV export | Performance tracking
NumPy
Used for:
Numerical computation | Matrix initialization | Scheduling simulation | Vectorized operations
sqlite3
Used for:
Persistent storage of benchmark instances | Structured data retrieval | Database-driven experimentation
random
Used for:
Stochastic solution generation | GRASP candidate selection | VNS neighborhood exploration
time
Used for:
Runtime control | Convergence measurement | Stopping criteria implementation
math
Used for:
Mathematical computations | Numerical evaluation
Matplotlib
Used for:
Gantt chart generation | Makespan visualization | Scheduling performance analysis | System Architecture Style
Scientific Computing Application
Characteristics:
-Algorithmic experimentation
-Metaheuristic optimization
-Iterative simulation
-Performance benchmarking
Metaheuristic Algorithms
-GRASP
-Variable Neighborhood Search (VNS)
-Iterated Local Search (ILS)
-Combinatorial Optimization
-Operations Research
-Statistical Analysis
-Scheduling Algorithms
The source code is not publicly available. This project is presented as a technical case study describing the system design, methodology, and performance results.
- Technology:
- Optimization Algorithms | Python
- Empresa:
- Universidad del Bío-Bío, Industrial Engineering Department
- Technology stack:
- Python | Pandas | pip | Sqlite3 | Numpy | time | math | matplotlib | Seaborn | Scipy | Statmodels
- Developers Team:
- Marco Antonio Parra Fernández
Felipe T. Muñoz
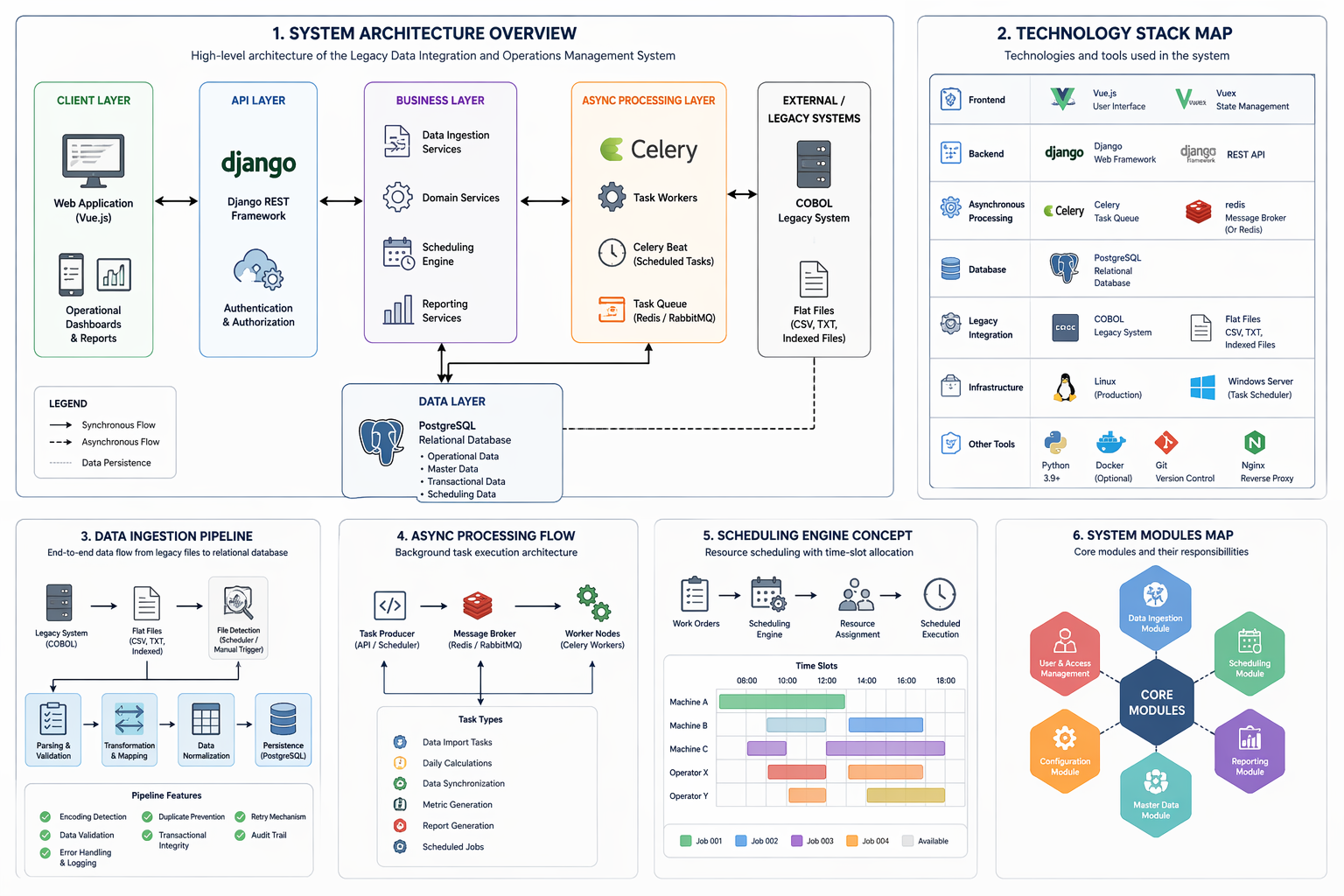
Legacy Production System Integration and Data Normalization Platform
- This project focused on the design and implementation of a backend integration platform responsible for bridging a legacy industrial production system built in COBOL with a modern relational data environment. The primary objective was to enable reliable synchronization of operational data generated by legacy batch processes into a structured, normalized domain model capable of supporting reporting, traceability, and long-term system evolution.
The legacy system produced large volumes of operational data through scheduled batch executions, exporting information into flat and indexed files stored on shared network locations. These files contained fragmented records representing products, technical specifications, production operations, and related master data without consistent referential relationships. To address this, a robust ingestion and transformation pipeline was developed to detect new files, validate structural integrity, normalize field formats, and map legacy identifiers into relational entities using the Django ORM and PostgreSQL as the primary persistence layer.
A key architectural responsibility of the platform was ensuring data integrity and consistency across asynchronous workflows. The ingestion process incorporated transactional safeguards, idempotent record creation strategies, and controlled synchronization logic to prevent duplication and maintain referential relationships between products, components, technical sheets, and supporting catalogs. Background processing was implemented using Celery workers coordinated through a message broker, enabling scheduled imports, periodic data reconciliation, and operational metric calculations without blocking application workflows.
Significant emphasis was placed on domain normalization and schema evolution. Legacy attributes originally stored as raw text fields were progressively migrated into structured relational catalogs using incremental migration strategies designed to avoid service interruption or data loss. This approach followed industry-standard patterns for safe schema evolution, including staged transitions, controlled data migration, and validation of referential integrity before deprecating legacy fields.
The system also introduced centralized catalog management and automated master data synchronization, reducing reliance on manual data entry and improving consistency across operational records. Logging, validation, and audit mechanisms were incorporated to support traceability of data imports and to provide visibility into batch processing outcomes, enabling operational teams to detect anomalies and maintain confidence in the integrity of production data.
From an architectural perspective, the platform was designed as a modular backend service capable of supporting future system modernization initiatives. Conceptual extensions were explored for advanced production scheduling and maintenance management modules, including resource allocation logic and availability modeling; however, these components remained at the design and prototyping stage and were not deployed in the production environment.
Overall, this project represents a practical implementation of legacy system modernization through controlled data integration, emphasizing reliability, transactional consistency, and maintainable system evolution within an industrial production context.
- Technology:
- Python / Django / VUE
- Empresa:
- Industrial Manufacturing Company (Confidential)
- Technology stack:
- Python, Django | Django REST Framework | PostgreSQL | Celery | RabbitMQ | Redis | CSV Processing | ETL Pipelines | ACUCOBOL-GT | Windows Task Scheduler | REST API | Data Normalization | Transaction Management | Background Jobs | File-Based Integration
- Developers Team:
- Marco Antonio Parra F
Single developer responsible for backend architecture, data modeling, legacy integration, ETL pipeline development, database migration, and system deployment.
AgriDrone Vision Evaluation Pipeline
- **AgriDrone Vision Evaluation Pipeline** is a generalized and anonymized technical case study of an applied computer vision and geospatial machine learning system for agricultural drone imagery.
The project documents the design of an end-to-end ML engineering workflow capable of processing high-resolution UAV images and videos, running object detection models, validating model performance, generating reproducible evaluation artifacts, enriching detections with geospatial metadata, and exporting results into formats suitable for GIS analysis, technical reporting, and downstream agricultural decision-support workflows.
At its core, the system focuses on applying **YOLOv8 / YOLOv11** object detection models to agricultural imagery captured by drones. The pipeline supports both direct YOLO inference and **SAHI-based sliced inference**, which is especially useful for high-resolution images where small objects may be lost during resizing. SAHI allows the image to be divided into overlapping slices, processed independently, and reconstructed into full-image detections, improving the ability to detect small or dense objects in aerial scenes.
The documented workflow includes several stages of the machine learning lifecycle: dataset configuration, model training orchestration, validation, benchmarking, automatic best-model selection, inference, post-processing, evaluation, visualization, geospatial export, and technical documentation. It is not presented as a simple model-training notebook, but as a broader ML engineering system that connects experimentation, inference, evaluation, and geospatial analysis.
The training and validation layer describes how YOLO models can be trained and evaluated across different configurations such as model version, image size, batch size, confidence threshold, device selection, and dataset structure. It also documents model-selection logic based on experiment metrics, allowing the system to identify the best available `best.pt` checkpoint from previous runs. The validation and benchmarking workflow includes global metrics, per-class metrics, inference timing, GPU-aware execution considerations, and reproducible artifact generation.
The evaluation layer includes COCO-style evaluation concepts, conversion of YOLO annotations and predictions into COCO-compatible structures, and the calculation of metrics such as AP50, AP50:95, precision, recall, and F1-score. The documentation distinguishes between YOLO-native validation metrics, COCO-style evaluation metrics, and operational inference outputs, making clear that each type of metric answers a different question about model performance.
The inference layer supports processing individual images, full directories of images, high-resolution drone imagery through SAHI, and video inputs. For static imagery, the system generates styled images with bounding boxes, class labels, confidence scores, per-image JSON metadata, batch summaries, and geospatial outputs. For video, the system documents a dedicated video inference and object tracking processor that uses YOLO tracking IDs to count unique objects across frames, render annotated videos, generate JSON summaries, and optionally produce frame-level SRT artifacts.
A major part of the project is the integration between computer vision and geospatial processing. The system does not stop at object detection. It enriches detections with EXIF/GPS metadata when available, converts latitude and longitude into UTM coordinates, and prepares structured spatial outputs for GIS workflows. These outputs may include GeoJSON, CSV, Shapefiles, QGIS-compatible summaries, and spatial metadata records. This allows model predictions to be inspected, analyzed, and visualized in geospatial tools instead of remaining isolated as pixel-space bounding boxes.
The project also documents a raster georeferencing workflow for styled detection images. This includes copying EXIF/XMP metadata from original drone images, generating JGW world files for styled JPEG outputs, documenting CRS assumptions, supporting optional GeoTIFF fallback, and enabling QGIS-oriented raster loading workflows. This raster-oriented layer is separate from vector outputs like GeoJSON and Shapefiles, and it addresses the practical need to visually overlay annotated detection imagery inside GIS tools.
The video processing component introduces a different type of complexity because video inference is not simply image inference repeated over frames. It includes temporal state, frame decoding, YOLO `model.track()` execution, extraction of bounding boxes and tracking IDs, unique object counting, rendering of overlays, video writing, SRT generation, frame-level error handling, and resource finalization. The documentation captures risks such as tracker ID instability, missing `box.id` values, RGB/BGR color-space issues, JSON serialization problems, and performance bottlenecks caused by frame-by-frame processing.
The system also documents important engineering constraints and trade-offs. These include SAHI runtime overhead, GPU/CUDA memory pressure, cuDNN runtime assumptions, filesystem-based experiment lineage, path fragility, lack of formal retry logic, absence of background workers, output idempotency concerns, metadata quality issues, CRS ambiguity, and the difference between a research-grade batch pipeline and a fully production-ready platform. These limitations are intentionally documented to show realistic engineering judgment rather than presenting the system as a finished enterprise product.
From a software architecture perspective, the project is organized around several conceptual services and processing layers: CLI orchestration, model selection, training, validation, benchmarking, inference, SAHI reconstruction, video tracking, geospatial enrichment, raster georeferencing, GIS export, reporting, and documentation rendering. The current public version describes these as generalized architectural components rather than publishing proprietary source code or institutional implementation details.
The repository is intended to demonstrate applied ML engineering capabilities across multiple domains: computer vision, object detection, high-resolution image processing, geospatial metadata handling, GIS integration, video analytics, evaluation methodology, GPU-aware workflows, and technical documentation. It shows how a machine learning pipeline can be extended beyond model inference into reproducible evaluation, spatial intelligence, reporting, and practical analysis workflows.
This public repository is a sanitized portfolio version. It does not include private datasets, source code from proprietary systems, trained model weights, real drone imagery, real field coordinates, real shapefiles, real GeoJSON outputs, production credentials, institutional or client names, unpublished experimental results, or confidential operational details. The documentation is presented as a generalized technical case study focused on architecture, methodology, engineering decisions, and system design patterns.
- Technology:
- AI / Computer Vision
- Empresa:
- Anonymized Agricultural Computer Vision R&D Case Study
- Technology stack:
- Python, PyTorch, Ultralytics YOLOv8/YOLOv11, SAHI, OpenCV, Pillow, NumPy, Pandas, pycocotools, ClearML, CUDA, cuDNN, EXIF/GPS metadata processing, UTM coordinate conversion, GeoJSON, Shapefile, JGW world files, GeoTIFF, QGIS, PyQGIS, GDAL/OGR, Markdown documentation
- Developers Team:
- Marco Parra
Demizona E-Commerce MVP
- Desarrollar una idea de negocio incorporando tecnologías web, considerando un desarrollo Full Stack hasta el deployment del proyecto.
Corresponde a un sitio de comercio digital que permita a productores locales de frutas y verduras vender sus productos a través de este sitio web, utilizando un sistema de búsqueda por categorías y productor.
La aplicación fue construida basada en la gestión de datos CRUD, de manera responsive y dinámica, utilizando Ruby On Rails, MySQL.
- Technology:
- Ruby On Rails
- Empresa:
- Freelance
- Technology stack:
- Ruby / HTML / CSS / JAVASCRIPT / BOOTSTRAP
- Developers Team:
- Daniel Acevedo / Pablo Martinez / Jorge Molina / Marco Parra
My Portfolio
- This project provides a compilation of professional experience, academic training, specializations, programming languages skills, and the most relevant projects I have participated in.
This web application was built with the language programming Python and used the Framework Django. The application business logic was realize used Postgres how database motor SQL. Deploying in the cloud was considered Heroku how provider.
- Technology:
- Django
- Empresa:
- Freelance
- Technology stack:
- Python Django HTML CSS SQL Postgres Linux Github Git JavaScript Heroku
- Developers Team:
- Marco Antonio Parra .F
Personal Blog
- This project built a blog website using Framework Django and in addition, using external libraries such as React Framework, Bootstrap, Crispy Forms, Django Allauth, Django registry, Django Rest Framework, and Simple JWT, among other libraries. Include connecting with SQL database using RDBMS Postgres.
- Technology:
- Django
- Empresa:
- Freelance
- Technology stack:
- Django / HTML / CSS / Crispy Forms / Bootstrap / JWT / Swagger / Rest Framework / drf_yasg / django_filters / versatile
- Developers Team:
- Marco Antonio Parra .F
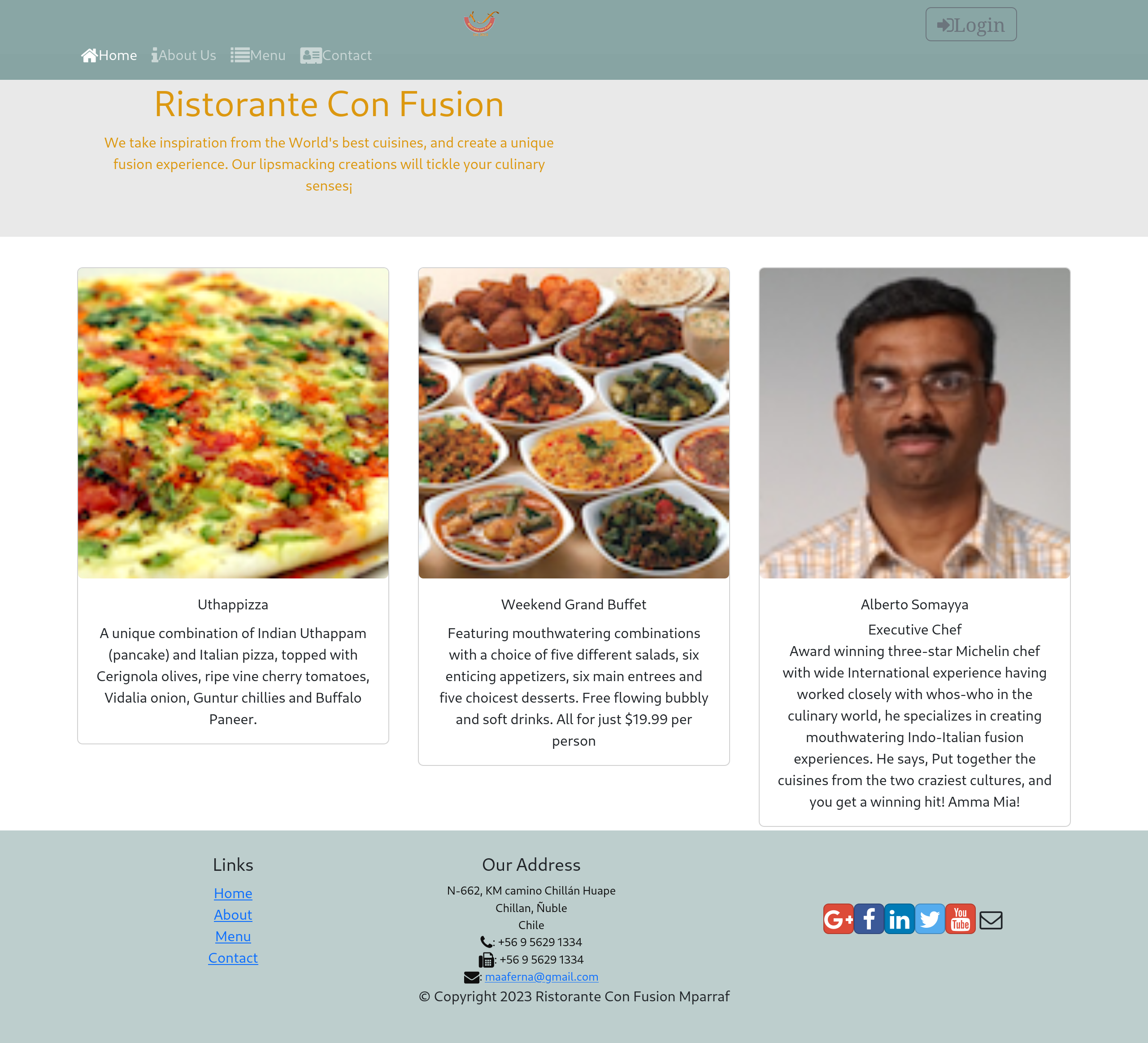
Restaurant ConFusion
- Restaurant web page using React, redux, reactstrap and json-server.
In the second part was included Server side with Node JS, database MongoDB and populate data with Mongoose.
This project was developed with React Framework and was used json-server to deploy data.
The second part of this project was included the Server Side, used NodeJs, Mongoose (to see more detail visit repository: https://github.com/maaferna/NodeJsProjectCoursera
- Technology:
- React
- Empresa:
- Freelance
- Technology stack:
- React / JavaScript / HTML / CSS / Redux / Reactstrap / Json-server / NoSQL / MongoDB / Mongoose / NodeJS
- Developers Team:
- Marco Antonio Parra .F
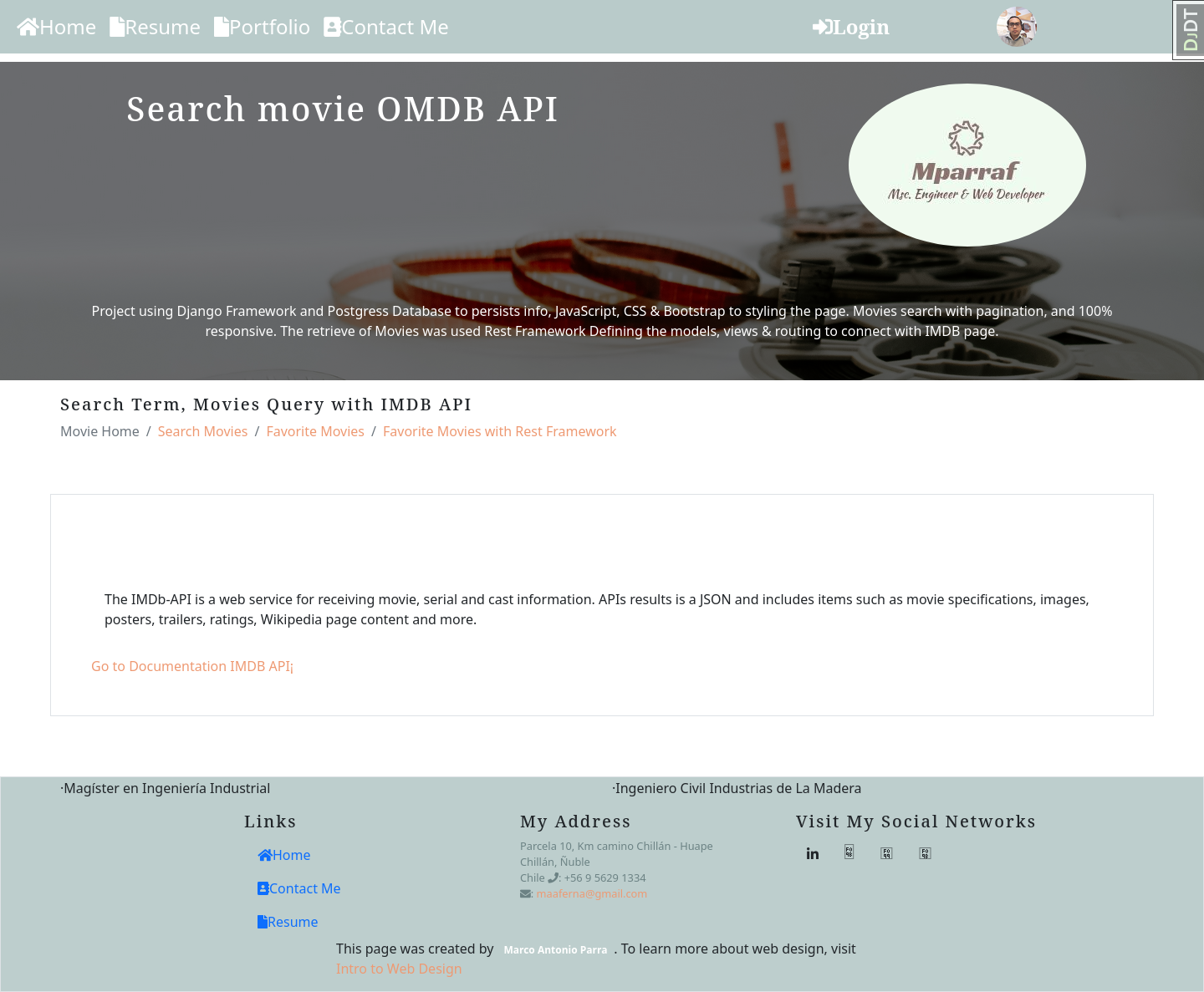
Movie IMDB API
- It is a project connected to the open-source API database IMDb, which gives a movie tracker and movie finder where you can find movies, series, seasons, and episodes. This application was developed in Python with Django Framework used a Postgres Database.
This application allows searching for movies and retrieving detailed information such as cast, ratings, and a review of these movies. The processing and manipulations of data were made with Rest Framework and Python functions to work with JSON format.
- Technology:
- Django
- Empresa:
- Freelance
- Technology stack:
- Django / Python / Rest_Framework / JavaScript / JQuery / Celery / Postgres / Bootstrap
- Developers Team:
- Marco Antonio Parra .F
Digidesk API
- Mini project application to fetch data from Digimon API, making dynamic and incorporating events so that the user can interact with the DOM. To consume data from API used the Fetch function in JavaScript, and also with Python methods.
- Technology:
- Django
- Empresa:
- Freelance
- Technology stack:
- Django / Python / JavaScript / JQuery / HTML / CSS / Heroku / Postgres
- Developers Team:
- Marco Antonio Parra
Data Science
- This project contains the source code and related files for resolving data science problems using Python. Explore external libraries how as Pandas, Matplotlib, Numpy, Beutiful Soup, Regex, and others.
- Technology:
- Django
- Empresa:
- Freelance
- Technology stack:
- Python / HTML / CSS /GitHub / Pandas / Matplotlib / Numpy / Beautiful Soup / Regex
- Developers Team:
- Marco Antonio Parra
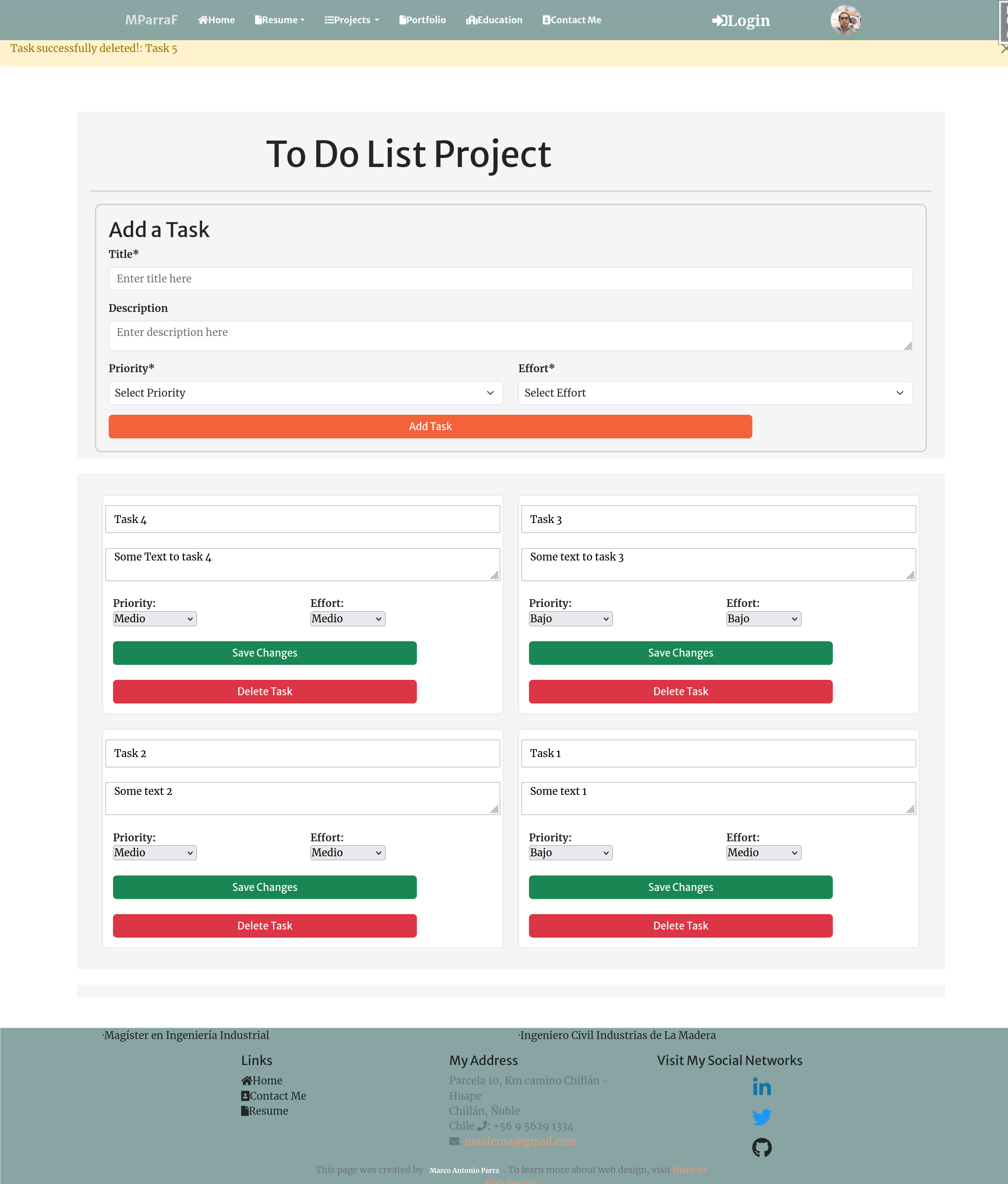
To Do List (Task Tracker)
- Create a modern task tracker application with robust token authentication, empowering users to manage their tasks efficiently. This project incorporates Django for the backend, Django Rest Framework for RESTful API development, and Vue.js for a dynamic frontend.
User Authentication: Implement token-based authentication to secure user accounts and ensure data privacy.
Task Management: Enable users to create, update, and delete tasks, keeping track of their progress and deadlines.
RESTful API: Utilize Django Rest Framework to build a scalable and maintainable API for seamless communication between the frontend and backend.
Dynamic Frontend: Develop a responsive and user-friendly frontend using Vue.js, providing an interactive task management experience.
CORS Integration: Configure Cross-Origin Resource Sharing (CORS) to allow secure communication between the frontend and backend on different origins.
- Technology:
- Django
- Empresa:
- Freelance
- Technology stack:
- Backend: Django / Django / Rest Framework / Djoser / PostgreSQL
Frontend: Vue.js / Axios
Authentication: Token-based authentication
Additional Libraries: Crispy Forms / Font Awesome / Bootstrap 5
- Developers Team:
- Marco Antonio Parra
Metaheuristics Optimization, NP Hard problem-solving

Precision Agriculture Object Detection Pipeline
Legacy Production System Integration and Data Normalization Platform
Blog projects
E-commerce Demizona
API IMDB Movie project
Restaurant Project ConFusion
Digimon API
To Do List(Task Tracker)
ABOUT ME

Hi there! I'm Marco Antonio Parra Fernández, a data engineer and full-stack developer based in Chillán, Chile.
I'm working on freelance projects involving data engineering and web development, bringing my Python, Django, Ruby on Rails, and React expertise to create innovative solutions.
I hold a Master's degree in industrial engineering from the University del Bío-Bío, specializing in operations research and optimization models.
As how professional in the IT industry I have a passion for learning new languages and problem-solving techniques.
My passion for technology and its applications has led me to pursue various professional certifications, including Python for Everybody, Applied Data Science with Python, Google IT Automation with Python, PostgreSQL for Everybody, and more.
As a data enthusiast, I have experience in data wrangling, machine learning, data visualization, and statistical analysis.
In my previous work experiences, I was involved in diverse projects ranging from technology transfer initiatives to optimizing production processes. This has given me a solid foundation in project management, process optimization, and team coordination.
I'm driven by a passion for web development and data analysis, constantly striving to grow and learn in the ever-evolving field of information technology. I believe in the power of teamwork and continuous learning to achieve remarkable results.
I'm committed to contributing to open-source projects and sharing my knowledge with the developer community. Let's connect and collaborate on exciting projects together! Feel free to explore my portfolio & connect on LinkedIn.
Looking forward to making a positive impact through technology!